
Prepared for Prof. Javed I. Khan
Department of Computer Science, Kent State University
Date: November 2004
| Media streaming | Anonymity Service | Distributed Computing | Lookup service | Business |
| PROMISE | Freenet | SETI@home | Chord | P2P Mobile network |
| GnuStream | Tarzan | Entropia | Yappers | electronic marketplace |
| Zigzag | Free Haven | DataSynapse | CAN | B2BI |
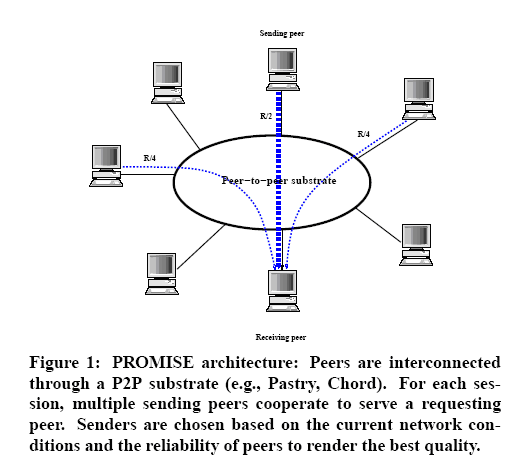
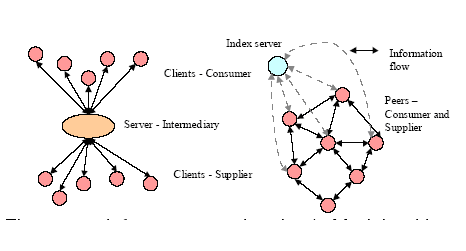

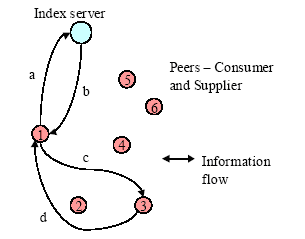
| P2P | Publisher | Reader | Server | Document |
| Freenet | Yes | Yes | No | Yes |
| Free Haven | Yes | Yes | Yes | Yes |
| Mojo Nation | Yes | Yes | No | Yes |
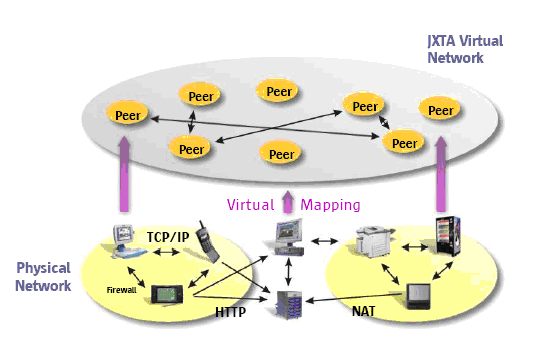
| Peer-to-peer systems | Model | Applications | Alternative | Business model | Research suggestions or Implemented already |
| Chord | Open-source | Lookup service | Yappers,CAN | Academic | Implemented |
| PROMISE | Open-source | Media streaming | GNUStream,zigzag | Academic | Not Implemented |
| FreeHaven | Open-source | Anonymity service | Tarzan,FreeNet | MIT research | In research |
| Electronic Marketplace | Open-source | Electronic transaction | none | Academic | Not Implemented |
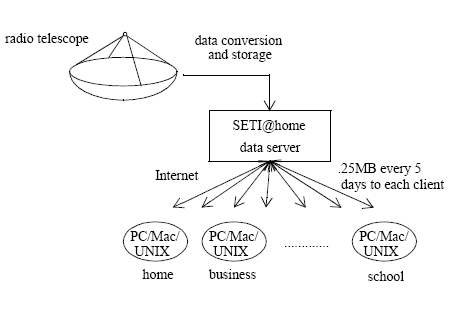
| SETI@home | Open-source | Distributed computing | AIDS@home,Cancer@home | Ads on screen saver | Implemented |
| JXTA | open-source proprietary extensions | File sharing,Email, messaging | .NET,My services | Common P2p platform | Implemented |