
Author : Vamsi C.Narra
e-mail : vnarra@cs.kent.edu homepage : www.cs.kent.edu/~vnarra
Prepared for Porf. Javed I.Khan
Department of Computer Science, Kent State University
Date : Fall 2004
Abstract : Content Delivery Networks(CDNs) has been a very useful tool in facilitating and optimizing the management and delivery of static or streaming content over IP networks such as corporate intranet, extranet and the internet. By ensuring that content is distributed and delivered closer to the end users. Many service providers, such as Akamai, Digital Island and Adero have implemented business models that offer better content distribution services. In my survey, i compare various access delay optimization techniques in CDNs that were proposed by various researchers, in order to provide latency guarentees to end users.
[Keyword] : CDNs,Access Delay Optimization,Latency Algorithms,Internet
Other Survey's on Internetwork-based Applications
Back to Javed I.Khan's Home Page
What is a Content Delivery Network
Description of Various Methodologies
What is a Content Delivery Network
CDN is defined as "a dedicated network of servers, deployed throughout the internet, that web publishers can use to distribute their content on a subscription basis." A CDN an overlay network of customer content, distributed geographically to enable rapid, reliable retrieval from any end-user location. CDNs use infrastructure technologies like caching to push replicated content close to the network edge. Global load balancing ensures that users are transperantly routed to the "best" content source. Stored content is kept current and protected against unauthorized modification. Customer-accessible traffic logs enable datamining for marketing and capacity planning.
Web performance is a complex engineering topic. Today's Internet architecture is based on centralized servers delivering files to all points on the internet. Bottlenecks can occue with this approach. Content access delay is the delay time elapsed from client's request to some CDN server until the requested content has been sent to the client, this includes the delay resulting from forwarding the request within the CDN if the initially accessed server does not have a local copy of the content and processing delays in CDN servers. Some of the reasons for the access delay are
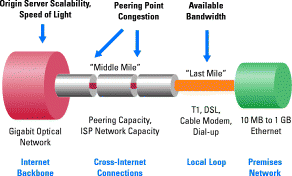
image courtesy of http://www.cisco.com
In this survey paper some of the access delay optimization techniques in Content Delivery Networks have been discussed and compared. These methodologies promise a better end user latency. Each of these techniques concentrate on various aspects of the CDNs such as shortest path, replication of content at the edges etc.
Replica-Aware Service Model
Content Division into Multiple Classes
Path Diversity Method
Pre-fetching Content
Two-layer Distributed Storage Model
Replica-Aware Service Model:
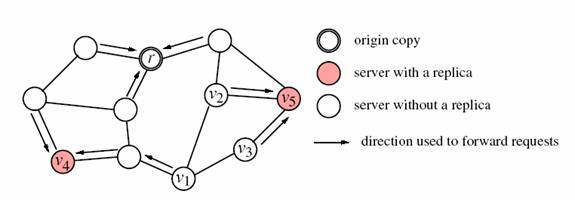
In the Replica-Aware service model, the servers in the system are aware of the replication strategy (the set of servers where the replicas are placed) by maintaining object identifiers and the associated replication strategies in the form of directories. By making use of this information, the servers are capable of directing locally missed requests to the nearest replica of the target object. By this redirection of requests the access delay perceived by the user is brought down to a great extent. In order to balance the server load due to the storage of replicas heuristic algorithms are used, such as Greedy-Insert and Greedy-Delete.
In the Greedy-insert, it starts with an empty replication strategy and replicas are inserted until all the QOS(quality of service) requirements are satisfied. These replicas are given a TTL(time to live) value after which they get deleted so that more replicas can be stored and multiple requests can be handled. In case of the Greedy-Delete, it starts with a complete replication strategy and replicas are deleted after their TTL values expire without any violation of the QOS requirements.The figure below shows a typical Replica-Aware Service Model where the requests are directed to the nearest server with the copy of the replica.
Content Division into Multiple Classes:
Content Distribution is designed to provide bounded content access latency. In order to achieve this content is divided into multiple classes with different onfigurable per class delay bounds. A simple distributed algorithm is used to dynamically select a subset of the network's proxy servers for different classes such that a global per-class delay bound is achieved on content access. The distribution algorithm achieves a 4 to 5 fold reduction in the number of response time violations compared to prior content distribution approaches that attempt to minimize average latency.
Operationally the network consists of a large number of content distribution proxies. Content providers negotiate with the distribution network for the intended service access latency of their content. The content distribution network dynamically determines the number and the locations of content distribution proxies that will need to host the content in order to globally guarentee the negotiated bound on the access delay.
Algorithm: It requires that every node know only its own span value and the number of nodes it can reach within the delay bound including itself. Each node sends its span (SPAN), i.e. the number of nodes that can download the object from it within the latency bound, to all the nodes it can cover and collects other nodes spans. The message specifies the span for each content class. If a node can only be covered by itself, the node has to be in the dominating set and sends a DOMINATOR message to nodes it can cover claiming that it is in the dominating set. Otherwise, after it gets SPAN messages from all the nodes that can cover it, or timeout, it chooses the node with highest span among them (which could be itself) and makes that node a member of the dominating set by sending it a NOMINATION message. When a node receives a NOMINATION message, it joins the dominating set. It then sends a DOMINATOR message to nodes it can cover and will not nominate another node if it has not sent out any NOMINATION message yet. Assuming no message loss, since every node selects a node that covers itself, when all nodes exit the algorithm the graph is dominated.
Path Diversity method:
This system improves the performance of streaming media CDNs by exploiting the path divesity provided by existing CDN infrastructure.Path diversity is provided by the different network paths that exist between a client and its nearby edge servers; and multiple description (MD) coding is coupled with this path diversity to provide resilience to losses. In this system, MD(multiple description) coding is used to code a media stream into multiple complementary descriptions, which are distributed across the edge servers in the CDN. When a client requests a media stream, it is directed to multiple nearby servers which host complementary descriptions. These servers simultaneously stream these complementary descriptions to the client over different network paths.
Algorithm: Shortest Path (SP): Pick the two closest servers (with different descriptions) to the client and measure closeness by hop counts. If more than one server has the same shortest path distance, a tie breaker is chosen randomly.
Pre-fetching Content:
This method concentrates on the reduction of the download latency experienced by each individual user to provide fast pervasive access to customized content. Consequently, the systems must make use of two sources of information. The first source provides information from application providers, describing application semantics and the interdependency between the application components. The second source provides aggregate information on the end user.
Experimental Setup:
Application Model-The application model consists of an interface component graph with nodes connected to an arbitrary number of web services. The interface component graph is a directed graph representing the interaction and dependency between all the different modules of the application. For example, these modules can be HTML documents or Java Server Pages (JSP), connected to each other by the links that allow user to navigate between them. The web service could be a set of Enterprise Java Beans that dynamically provide content to both the HTML or JSP nodes of the interface component graph.
User Model-The user model is a description of general properties of the end user.
Computational Capability: Computation capability is the information about a user that is exploited in most existing content delivery systems. It includes standardized descriptions of the computational capabilities of all the devices present in the user’s environment. The description includes attributes such as screen size, color depth, storage capacity, CPU speed, etc.
User Context: User context includes all the user characteristics related to his or her environment.
User Preferences: User preferences are a representation of the content access habits of the user. Preferences can be viewed as either deterministic or probabilistic. Deterministic preferences are obtained directly from the user via subscription, whereas probabilistic preferences are inferred by the system from the user’s past request patterns.
User State: User state is composed of three attributes: the physical location of the user; the state of the applications that he is currently accessing; and which devices are active in his environment. These attributes define a virtual computer composed of the active devices at the user’s location.
Experimental Test-bed: A system is developed to test the hypotheses about the extent to which pre-fetching content can reduce the latency of pervasive applications. The initial experiments pre-fetch content based only on deterministic user models but not on application models. The main hypothesis being tested, is that with a small amount of prediction on usage patterns of end users, preparing the edge of the network can significantly reduce the overall end-to-end delays observed by the users. Accordingly, the performance metric being employed is the average latency experienced by a user when accessing a particular piece of content.
Two-layer Distributed Service Model:
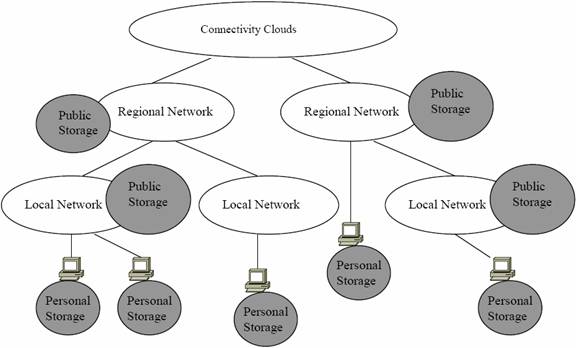
Here a scalable information dissemination architecture called KAESAR(Kaist Information Dissemination System Architecture) is used with the global application of resources. This method shows how key technologies such as caching, replication and multicasting could be integrated to form a scalable information dissemination architecture. Caching and Replication help in reducing access delay and bandwidth consumption while Multicasting improves the scalability of information dissemination system.
Model Functionality: A two-layer distributed network storage model is proposed, as a component of scalable information dissemination architecture, KAESAR. KAESAR adopts a hybrid architecture in which traditional client-server systems and peer-to-peer systems are combined and harmonized together. It consists of two different kinds of network storage, Public Storage and Personal Storage. Public Storage is large and static serverbased storage, which is built for public usage. Caches, mirrors, replicas, and Internet Archives are typical examples. Personal Storage means storage resources attached to end-users' desktop PCs but are approved and donated by owners, for public usage. As a natural complement to Public Storage, Private Storage makes KAESAR a highly scalable architecture by being allocated or de-allocated dynamically, to form a gigantic virtual storage and facilitate efficient dissemination of information. The figure below shows the Two-layer Distributed Network Storage Model.
| Categories | Replica-Aware Model | Content Division into Multiple Classes | Path Diversity Model | Pre-fetching content | Two-layer Distribution service Model |
|---|---|---|---|---|---|
| Access delay optimization based on | Replicating Contents at Servers | Division of Content into Multiple classes with Different Configurable per-class Delay Bounds | Optimum Path Between Client and Server | reduction of Download Latency abd providing better Access to customized content | Caching, Replication and Multicasting are used in order to reduce access delay |
| Algorithm Used | Geedy-Insert and Greedy-Delete | SPAN Algorithm | Shortest Path | Experimental Setup | KAESAR Architecture |
| Type of experiments | Real Time | Simulation | Real Time | Simulation | Simulation |
In brief, the various access delay techniques in Content Delivery Networks concentrate on different aspects of the network in order to increase the user perceived latency were studied. Each of these methods have their own advantages and disadvantages. Of all these techniques the most efficient ones are the replica-aware service model and the path diversity model. Both of these model have been implemented and are producing results upto a great extent. There is still extensive research going on to reduce the access delay to the end-user. The pre-fetching model requires a system to be designed such it has all the properties of the user and the application which is not possible for implementation, since the service providers cannot take the management overhead of collecting all this information. Some of the overall research challenges are to satisfy the QOS requirements of clients especially the access latency. Also the biggest challenge is to implement these methods and make them usable over the Internet. Right now very few are being implemented. It would interesting to see how well these systems work with millions of user requests over the internet, and how efficient are these methods in making use of the resources.
Towards Content Distribution Networks with Latency Guarantees Chengdu Huang and Tarek Abdelzaher
On Multiple Description Streaming with Content Delivery Networks John Apostolopoulos, Tina Wong, Wai-tian Tan, Susie Wee
Preparing the Edge of the Network for Pervasive Content Delivery Daby M. Sow, Guruduth Banavar, John S. Davis II, Jeremy Sussman, Mugizi R. Rwebangira
KAESAR : A Scalable Information Dissemination Architecture on the Internet Hyunchul Kim, Kilnam Chon
Accelerating Internet Streaming Media Delivery using Network-Aware Partial Caching Shudong Jin, Azer Bestavros and Arun Iyengar
Network optimization with Enterprise Application Management By Richard Heaps, Products & Solutions - Equant
Enabling CDN for Live Streaming: A Server-CDN Joint Perspective Yunfei Zhang, Changjia Chen
On the Optimal Placement of Web Proxies in the Internet BoLi, Mordecai J. Golin and Giuseppe F. Italiano and Xin Deng
Optimal Content Placement For En-Route Web Caching Anxiao (Andrew) Jiang and Jehoshua Bruck
Lancaster University E-NEXT Initiatives
Market Analysis and Projections for Web Caching and Content Distribution
This survey is based on research publications found in ACM Digital Library and IEEE Journal. The search was done based on the keywords that were mentioned above and looked at several of the articles that were listed in the results. The keywords used were CDNs, Access Delay Optimization, Latency Algorithms, Internet.