A Tutorial on Gnutella, Bittorrent and Freenet Protocols
Author: Chibuike Muoh
email: cmuoh@kent.edu homepage: www.cs.kent.edu/~cmuoh
Prepared for Prof. Javed I. Khan
Department of Computer Science, Kent State University
Date: May 2006
Abstract:
Peer-to-Peer networks are popular applications in content-sharing networks because they provide better scalability and fault tolerance than the client/server model of computing. The P2P model of computing has many applications in distributing processing, remote collaboration networks and communication networks but for the purpose of this survey we only consider P2P protocols that allow peers to share and access resources. In particular we examine the protocols of popular peer networks of Gnutella, Bittorrent, and Freenet. For each system examined we concentrate on the underlying principles and examine how sharing of resources is achieved using its protocol.
Table of Contents
1. Introduction
1.1 What is P2P?
1.3 Criteria for evaluating P2P systems
2.1 Gnutella
2.2 Bittorrent
2.3 Freenet
3. Conclusion
4. References
4.2 Research groups
1. INTRODUCTION
1.1 What is Peer-to-Peer?
Peer-to-peer can be described as a network of cooperating peers that work together to complete tasks and access resources in the network. Peer systems are scalable and fault tolerant in their approach because they offer no single points of failure, and the network can grow and shrink without sacrificing the functionality of the system. Some of the more interesting points on the desirability of P2P system are:
- Ad-hoc and dynamic membership allows the P2P systems to be self organizing and can easily scale up/down as the number of peers can grow
- Better bandwidth utilization since the peers communicate directly with each other
- Fault tolerant since no one node is more important the other
- Richness and diversity in services/resource available in the network
1.2 Impact of P2P today
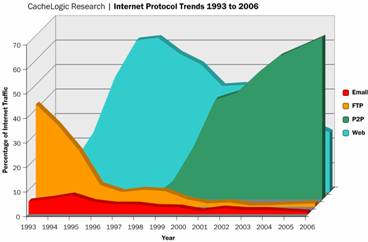
Although P2P has several applications but by far the most popular application of P2P system is in content sharing networks which is the main focus of this survey. Current statistics from CacheLogic, an internet services company show that P2P traffic makes up about 50%-65% of the downstream traffic for major ISPs and 75%-90% of their upstream traffic [13].
|
Figure 1.2.1: Internet protocol trends (Source: David [11]) |
1.3 Criteria for evaluating P2P systems
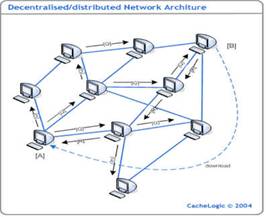
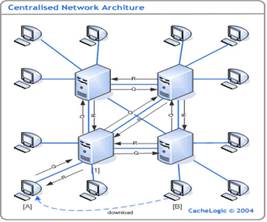
P2P systems can generally be broken down into two broad classes [1][12]; Pure and Hybrid P2P systems. In pure P2P peers act as both clients and servers in the network, they are thoroughly decentralized; nodes have equal role/capability and peer communication is symmetric. Pure P2P has the advantage that they are truly dynamic and less vulnerable to downtown time since there is no critical component. Hybrid P2P system differs in its use of central severs or “super nodes” for the sole purpose indexing of the resources or allocating tasks in the system. This allows it to offer better performance than pure system at the expense of being limited by the availability of the indexing servers. Peers in the hybrid system are still responsible for hosting the resources on the network and can directly contact other peers to initiate access to remote resource.
|
Figure 1.3.1: Pure P2P network (Source [17]) |
Figure 1.3.2: Hybrid P2P network (Source [17] |
P2P computing is a fast evolving field and over its history there have been several variation and approaches to implementing peer computing. First there was Napster, a music sharing file network that brought the use of P2P technology into the lime light. The Napster system was unique at its time because it allowed peers to download music files directly from other peers on the network (which had very strongly connected components). Sadly though, the history of Napster was abrupt (Sept. – Dec 1999) due to legal issue of copyright violations that virtually forced the network out of existence.
Though Napster’s history was short it had a huge impact on the way people used the internet (being the dominant P2P applicant in existence at the time) and also popularize the whole P2P movement. Subsequent P2P file sharing application started to appear after its fall (e.g. Kazaa, Ares, Morpheus etc.) and they sought to avoid the pitfalls of the Napster protocol by making their operations more decentralized in order to avoid legal liabilities, but no single one of them have been able to maintain dominance compared to Napster although it is important to point out that the volume of the P2P on the internet has increase significantly over the years (figure 1.2.1).
For this survey, we examine the Gnutella, Bittorrent, and Freenet protocols, which are some of the most dominant P2P protocols for content networks [13] in terms of their approach to the P2P concept and popularity on the internet. Gnutella represents one of the first systems that gained huge following after the downfall of Napster, its simple but scalable design and its distributed nature allowed it avoid the legal pitfalls that plagued other more centralized networks.
Following from the original Gnutella model, other peer networks have adopted its concept and applied it in different ways (e.g. E-Donkey, Aires, Morpheus) but Freenet represents a significant evolution of the original Gnutella network model; it make security and anonymity of peers central components of the network (a feature which was ‘missing’ from the original Gnutella protocol). Also Freenet is significant for this survey because its enhancements to the basic search mechanism in Gnutella made locating data in the network was more efficient without have to result in a centralized model by introducing indexing servers.
The choice of Bittorrent for this paper is made clear both the popularity of Bittorrent networks in content sharing and its radical approach to effectively apply fairness principles in peer networks; no other popular network models known to efficiently and effectively apply fairness rules in P2P while maintaining “high levels of robustness and resource utilization” [5].
2.1 Gnutella
First developed by Justin Frankel and Tom Pepper of Nullsoft (later acquired by AOL) in 2000 and released under the GPL license the Gnutella protocol presents a simple framework for sharing files on the internet that is scalable and robust.
Gnutella falls into the class of pure P2P; peers in the network are joined by point-to-point connections to a set of neighboring peers to form an unstructured overlay. These point-to-point connections in Gnutella are maintained using predefined messages described by the Gnutella protocol (table 1). In order to join the Gnutella P2P network a peer has to contact a known member of the network and request to establish a Gnutella protocol connection to the remote peer, once connected to the network new peers learn about other nodes through the protocol message they receive from the network.
Initial discovery of known peers in the network is not part of the protocol definition, (though some out-of-network means such as downloading a predefined list of known peers from a server are popular methods). Once a Gnutella peer obtains an address for at least one known peer in the Gnutella network to try to initiate a TCP/IP connection, and next a Gnutella protocol connection request string is sent over the connection to the remote peer to establish the Gnutella connection. The connection string is in the form “GNUTELLA CONNECT/<protocol version string>\n\n” where the <protocol version string> is an ACII string indicating the protocol version number the requesting peer is using. The remote host replies with “GNUTELLA OK\n\n” if it wishes to accept incoming connection. A peer joining the network shares an area in its local storage by creating an inverted list of files that are contained in the share space and evaluates queries it receives from the network against the inverted list.
|
Type |
Description |
Contained information |
|
Ping |
Used to actively discover hosts on the network. A peer receiving a Ping descriptor is expected to respond with one or more Pong descriptors. |
None |
|
Pong |
The response to a Ping. Includes the address of a connected Gnutella peer and information regarding the amount of data it is making available to the network. |
IP address and port number of the responding peer; number and total kB of files shared |
|
Query |
The primary mechanism for searching the distributed network. A peer receiving a Query descriptor will respond with a QueryHit if a match is found against its local data set. |
Minimum network bandwidth of responding peer; search criteria
|
|
QueryHit |
The response to a Query. This descriptor provides the recipient with enough information to acquire the data matching the corresponding Query. |
IP address, port number, and network bandwidth of responding peer; number of results and result set |
|
Push |
A mechanism that allows a firewalled peer to contribute file-based data to the network |
Peer identifier; index of requested file; IP address and port to send file to |
Table 2.1.1: Showing the message types in the Gnutella protocol (Source [3])
Gnutella uses TCP as its underlying transport protocol but it is abstracted by an application level protocol which describes how peers communicate. Each message in the network is always preceded by a descriptor header message that describes the payload of the Gnutella message. Message descriptor headers are assigned unique identifier so that a peer that has already seen a message before can ignore it (helps to avoid looping in the network). Descriptor headers also have a TTL (Time-To-Live) value and a hops count value which keeps track of the times the message has been forwarded. Messages received by a peer are forward to other peers that are connected to it, in this way message are flooded in the network to ensure it reaches it intended destination.
To control the scope of flooding of Gnutella messages, the TTL value is set in the descriptor header specifying the number of times the message should be forwarded before it can be discarded. In the example below (figure 2.1.1) when a peer receives a ping message from a new peer in the network, it replies back with a pong message and decrements the TTL value of the message. The ping message is forwarded to other neighboring nodes which reply with a pong and decrement the TLL value. Once the TTL value of the message is zero, the message is dropped from the network.
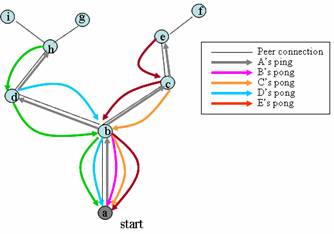
Figure 2.1.1: propagation of ping messages in the Gnutella network from peer A with TTL set to 2
Distributed discovery of resources in the Gnutella P2P network works in much the same way as sending ping/pong message in the network; the initial query is generated by a peer and sent to neighbor peers directly connected to it, these neighbor peers evaluate and then forward the query to other neighbor peers. Peers that receive the query message evaluate it against its own data store and if they have resources that match the query respond back with a QueryHit message to the original peer.
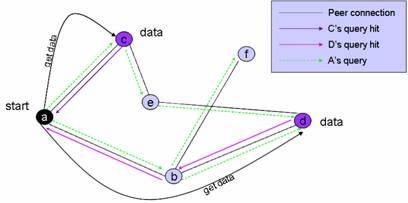
Figure 2.1.2: Searching in Gnutella
Once the query initiator has aggregated the responses to its original query, it initiates download of the resource by contacting the source peer “out of network”. The Gnutella protocol does not support file download over its application level protocol rather a target peer must contact the source peer directly using IP routing to establish a HTTP connection to download the file.
2.2 Bittorrent
Bittorrent represents a major innovation in the world of P2P computing. The protocol created in 2002 by Bram Cohen and was intended as an efficient and scalable alternative to current methods of file distribution in today’s P2P networks. By its self Bittorrent is not a full fledged P2P content sharing protocol, but it relies on other global components to allow users in the network locate file and work in P2P fashion [6].
One of the main problems in current P2P system is that they do not scale well when downloading large files. A typical internet connection has high download and significantly lower upload, so in the traditional method when downloading file the source peer bears the grunt of the download since it must appropriate portions of it limited upload bandwidth among the requestors of the file. This approach is neither scalable nor efficient and ensuring fairness in the system would result in poor download rates for all downloaders.
The Bittorrent protocol solution to ensure fairness in P2P was to split the files into little pieces of same length (~256kB, with exception of maybe the last piece) which are then traded between peers in a tit-for-tat manner. File pieces are downloaded in an unordered fashion from the source so that peers can exploit the use of peer connection to other downloaders to obtain file pieces they do not have. This novel approach in the Bittorrent protocol achieves “pareto” efficiency by redistributing the cost of file download among the peers in the network and helps to prevent parasitic behavior in the network [5]; using tit-for-tat method for trading pieces, peers with high upload to other peers with probability will download faster
File pieces in Bittorrent are described in a small meta-info text file that ends with a .torrent suffix. A .torrent files is a bencoded (an encoding format used in Bittorrent to store and transmit .torrent file in the network) dictionary that contains information about the file pieces that makes up the original file (Figure 2.2.1).
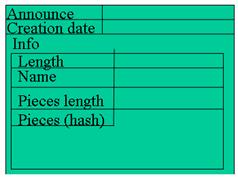
Figure 2.2.1: Structure of a .torrent file. The hash value of the file pieces is used as a checksum allowing nodes to check the validity of a piece that they have downloaded
Peers download files by participating in a file swarm which is an ad-hoc network of peers that are temporarily assembled to distribute a particular resource. Since Bittorrent is not really a P2P content sharing protocol, it relies heavily on global components to allow nodes locate resources and also find each in the network. The global components in a Bittorrent P2P network include torrent servers, web search engines and the tracker server. Communication between the peers and global component of Bittorrent P2P are passed through simple HTTP request/response messages.
Torrent servers in Bittorrent are ordinary web servers on the internet functioning as a data stores for .torrent file. Users wishing to share files in the Bittorrent network first have to create a .torrent file (figure 2.2.1) and upload it to a torrent server so other peers can obtain it (figure 2.2.2). To reduce pollution (insertion of low quality or garbage files) in the network, a moderator system is used to weed out fake content [6]. There are three levels of moderatorship in the network: moderators, unmoderated submitter, and moderated submitter. A normal user who injects content irregularly is called a moderated submitter. Users who frequently upload “quality” content can be granted the status of un-moderated submitter; they are allowed directly inject content into the system without peer review by moderators. Moderator status in a Bittorrent P2P network is the equivalence of system administrator for the torrent server; they have complete control over what can be inserted into the network.
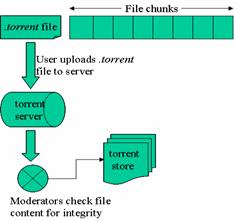
Figure 2.2.2: Torrent server in Bittorrent P2P networks
The role of web search engines in the Bittorrent P2P network is to allow peer locate the .torrent meta data file on the network. Web search engine play the role of a global directory (indexing server) of available resource in the Bittorrent P2P network; they accept user queries for a .torrent and return a resultset page of all possible match.
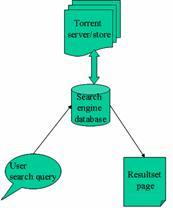
Figure 2.2.3: Interaction between torrent servers and web search engines in the Bittorrent P2P network
|
Terms |
Definitions |
|
Seed (seeder) |
A peer with a complete copy of the resource and still offers it for upload (seeding) |
|
Leech (lecher) |
Peer that contacts other peers to barter for chunks |
|
Swarm |
Together, all peers downloading a resource |
|
Choke |
Mechanism which allows client to prevent other clients from uploading to it. |
|
Share ratio (availability) |
Ratio of complete copies of the file in the swarm. Is expressed as a percentage of number of peers with copies of the file and total number of peers in the swarm. Each peer with complete copy adds 1 to the total. A peer with only a fraction of the complete file adds the fraction to the availability |
Table 2.2.1: some terminology in Bittorrent networks
Trackers in the Bittorrent system play a central role in the downloading of file in the swarm. They are responsible to help downloader locate one another in the system by keeping track of the seeders and downloaders of a file. Peers wishing to participate in the swarm for a file must first obtain the .torrent file to find out which tracker holds tracking information about the file and other important information about the file.
Participants in a file swarm use the tracker as an intermediary to gather download statistics (figure 2.2.4); peers report to the tracker information about what pieces it has, its download & upload rate, its IP address and port the Bittorrent client application is running on. Each peer poll the tracker for information about other peers in the file swarm to find suitable peers to trade pieces. Trackers respond to each request with a random list of peers that are participating in the swarm. This property allows for robustness in the file swarm by ensuring that peers with fast and slow connections have equal opportunity to maximize their download rate [5].
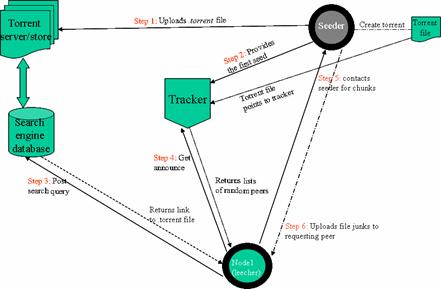
Figure 2.2.4: Bittorrent file swarm
Peers continuously trade piece with other peers in the network until they have obtained the complete set of file pieces needed to reassemble the original file. The order in which pieces are request from other peers in Bittorrent is optimized to improve their download rates. For peers that are new in the file swarm (with no piece to trade) it is important that they obtain a complete piece as soon as possible to start trading, so they used random piece selection algorithm for selecting a piece to downloaded quickly. Once a peer has at least one complete piece to trade, it changes its strategy of piece selection by choosing to download rare pieces in the network, this increases the probability that peers will have blocks to exchange in the event that a seeder goes offline.
For file downloads to be successful in Bittorrent, at least one peer (seeder) with the complete file must participate in the swarm until the complete set of file pieces has been fully disseminated in the network, as a result this allows Bittorrent to efficiently handling “hot spots” or requests for large files [6]. In the case of a large file, the seeder must stay online long enough until at least one peer has successfully downloaded the file or subsets of the full set of file pieces in available on peers the network. Eventually as more peers in the system complete their download and remain as seeders in the network, request for file start to complete quickly since each new peer participating in a file swarm adds additional upload bandwidth.
2.3 Freenet
Freenet is a highly decentralized system for secure and anonymous publishing and retrieval of information [15]. The idea was first conceived in a paper published by Ian Clarke et al [7] in 2001. It was designed to address the following issues in P2P systems:
- Security
- Publisher and consumer anonymity
- Deniability for storers of information
- Data replication for availability & performance
The above emphasis for Freenet networks makes it unique from the traditional P2P concept since the focus on security and anonymity are concepts that seem to contradict the open notion of peer-to-peer communication. However for the purpose of this survey we consider the underlying ability of the Freenet protocol to allow nodes share content/resource securely in P2P fashion.
Freenet operates as an unstructured network of nodes that poll their unused disk space to store data files in the network and cooperate to route request to the most likely physical location [7]. In some respect, the Freenet network is similar to pure P2P networks, however in Freenet, owners of a node cannot control what is being stored on their machine since placement of data in the system is done in a distributed manner and the file stored on each node is encrypted to ensure deniability.
|
Message |
Description |
|
Request.HandShake |
Sent by an unconnected peer to a remote peer to request a Freenet peer connection |
|
Reply.HandShake |
Reply by a remote that is available to establish connection |
|
Reply.Data |
Request for data (query) |
|
Send.Data |
In-protocol mechanism for resource download |
|
Request.Insert |
A request to insert resource into the network |
|
Reply.NotFound |
Returned when search or insert transaction failed |
Table 2.3.1: showing types of messages in the Freenet protocol
The basic means of communication between nodes in the network takes the form of messages whose function is described in the Freenet protocol (table 2.3.1). Each message consists of a 64-bit transaction ID that allows nodes to keep stateful information of messages that is routed through them in the network. Messages also include a TTL (Time-To-Live) and depth counters; the TTL counter is decremented at every hop to control the spread of the message in the network and the depth counter is used by a replying node to set TTL to a high enough value to reach the requesting node.
|
Protocol layer |
Description |
|
Application layer |
This defines the actual messages that are passed, encoded as per the previous layer, and the prescribed behavior of nodes upon receiving messages |
|
Presentation/Message layer |
This simple layer defines the format in which FNP messages are sent across the network. |
|
Crypto session layer |
This layer sets up the cryptographic link between nodes. This handles the authentication of nodes, the establishment of a cryptographic session, and defines how data sent is encrypted. |
|
Transport Layer |
Using traditional TCP/IP or other types of transport protocol |
Table 2.3.2: showing the Freenet protocol layer (Source [9])
Nodes in Freenet are arranged in a loosely structured overlay network similar to Gnutella; they are connected to a set of neighbor nodes which they route message to/from. Peers join the Freenet network by discovering address of one or more existing members of the network. Again like the case of Gnutella, discovery of known peers in the network is not part of the protocol definition although out-of-band means such as downloading list of peers from a server or manually supply the Freenet node with an address of peers to contact are popular ways to setting up initial connection to the network. After a remote Freenet node is contacted, a secure channel is built over the TCP/IP transport layer and the new node sends a Request.HandShake message to the remote peer to initiate a Freenet connection. If the remote peer is active, it can reply back with a Reply.HandShake message indicating that it accepted the connection request. Connection states in Freenet are treated as sessions and are only remembered for a few hours.
The Freenet protocol consists of 3 layers of abstraction (table 2.3.2) over TCP/IP which is used as the main transport layer in the network (although Freenet was designed to be used independent of which transport protocol it is run on). Message passing between nodes in the network occurs in the presentation/message layer and its operation is similar to Gnutella networks but in Freenet, messages are propagated to one neighbor at a time using a steep-hill-accent approach: once a peer receives a message it has seen before, it disregards it and the propagation process unwinds to the preceding node which chooses a different node to route to.
To prevent the possibility of an attacker unmasking the destination or origin of messages that passes through the network, reference to the final destination peer and route history of a message is removed and replace with the address of the peer that last routed the message; in this way, peers in the Freenet network only have knowledge of their immediate upstream neighbors. Also, messages in the network are forwarded with finite probability when hops to live reaches 1 to reduce the information an attacker can deduce from the TTL value in a Freenet message [7][8].
Nodes in the Freenet network maintain a local data repository that it makes available on the network for reading and writing. Data files in Freenet networks are encrypted using either a descriptive text (table 2.3.3) or with a public/private key pair which is hashed to produce a file key. Files are stored and referred to in the network by the file key. There are three basic methods to generate keys for files stored on the network,
- Keyword Signed Keys (KSK): This type of key is the most basic but insecure method to generate keys in Freenet. It is derived from the descriptive text of the file which is used to generate a private/public key pair. The public key is hashed to yield the file key, and the private key is used as a sign to verity the authenticity of a file when it is downloaded from the network. Using KSK the file publisher of a file only has to publish the descriptive text for the file to allow other users to locate it in the network.
- Self Signed Keys (SSK): This type of key alleviates the problem of key space collision when using KSK. Using SSK, publishers generate a namespace of key for files that they wish to insert in the network. The self signed keys are a public and private key pair; only the user with the private key can insert files into the network. The descriptive text is used to encrypt the file and the public key is used as a sign for the file.
- Content Signed Keys (CSK): This type of key is obtained by directly hashing the contents of the file to be inserted into the network. The key generated is used to encrypt the file before it is inserted into the network.
|
freenet:KSK@text/philosophy/sun-tzu/art-of-war.doc |
|
Table 2.3.3: An example of a Freenet file descriptive text. They are always proceeded by the ‘freenet:’ prefix. The next three characters denote the method for generating the key. The characters after the ‘@’ sign includes the files descriptive text. |
The routing protocol in Freenet uses a heuristic scanning of key techniques to determine the most likely destination/source for a file key; the target file key is matched for closeness with entries in the routing table to determine the next node to route to. Nodes in the network have a local routing table that contains entries for file keys that is stored in its local repository and entries for files keys it “knows” is reachable through nodes it is connected. The association of file key to nodes in the routing table is an ordered list based on a node’s previous performance on retrieving keys that are lexicographically similar [8][15]. Once a request message for a file key is received, a node first checks if it holds the data in its local data store before routing to a next hop.
To share a file in Freenet, the file has to be “inserted” into the Freenet network. A Request.Insert message is sent to the user’s node to insert the combination of file key and data into the network. In Freenet, files are stored in a location independent manner. This placement of data is determined by its routing protocol. Once a node receives a request to insert a file in the network, it saves the file in its local store and tries to route the insert message to a neighboring node; the heuristic scanning of keys in a node’s routing table determines which neighbor nodes would be “most interested” in storing the new content. The TTL value specified in the insert message is used to control the scope of the insert message in the network. Since each node in the network only has a limited amount of space to cache documents, older less recently used document would get deleted from the network to make room for more popular content.
Freenet insures that files are dynamically replicated in the system to ensure it availability and survivability. To prevent a malicious user from trying to overwrite existing files, by inserting data in the network with an already existing file key, the propagation of the insert message in the network starts to unwind at the point when a key collision is noticed; the node returns the pre-existing file as if a request has been made for it.
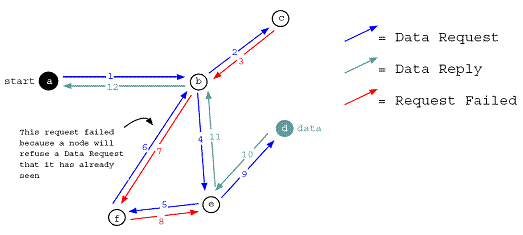
Figure (2.3.1): Showing how file searches in the Freenet network function. In this graph, vertices represent nodes in the Freenet network, and the directed edges are the sequence of peer communication in the network (Source [8])
Searching in Freenet networks only support exact match queries using the file keys, it is not possible to perform a range/blind search in the network. To search in the network, a user posts a query to its local node containing the descriptive text of the file to be retrieved from the network. The node hashes the descriptive text to obtain a file key and the routing algorithm is used to determine the likely location of the file in the system. If no match is found a Request.Data message is routed to a next hop node till a Reply.NotFound/Send.Data message is received or when TTL have reaches 0. In the case that a Reply.NotFound message is return, the originating node tries the second next hop for the file key.
Once a match for the file key is found, a Send.Data message, containing the file requested, is routed from the source node to the querying node by back-tracing along the path through which the query was routed (figure 2.3.1). In Freenet, nodes along the response path for a file key caches the file key and data combination this is done to improve performance for subsequent searches. One of the main side effects of this behavior is that nodes eventually become specialized in locating a set of similar keys [4][7] and data in the network would eventually be replicated about its most frequent requestors.
In this paper we surveyed the protocols of some of the most dominant P2P content sharing networks. The protocols surveyed differ in their approach from the early P2P networks, learning from the legal troubles of Napster, current P2P systems are pushing towards a decentralized approach (with the exception of Bittorrent, which is not a full P2P content sharing protocol). This push towards pure P2P has allowed the development of protocols to address some of the challenges of peer networks such as security, anonymity, scalability, fairness and robustness in the networks. Each one of the protocols surveyed addresses some of the challenges in the implementation of their protocol.
A major drawback for the protocols surveyed is that searching is quite expensive, with the exception of Bittorrent networks that use a hybrid structure, the search mechanisms provided in the Gnutella and Freenet networks are not efficient because network resource and bandwidth is wasted through the flooding of query message in the network. Also the protocols of Gnutella and Freenet define no standard way for new nodes to join the network. This is an issue especially for Freenet because the current methods used to identify nodes to connect to are not secure and go against the principle of preserving peer anonymity.
[1] Siu Man Lui and Sai Ho Kwok, "Interoperability of Peer-To-Peer File Sharing Protocols". In ACM SIGecom Exchanges, Volume 3 Issue 3, June 2002.
[2] Karl Aberer, Manfred Hauswirth, "An Overview on Peer-to-Peer Information Systems". In Proceedings of Workshop on Distributed Data and Structures, 2002
[3] Stefan Saroiu, P. Krishna Gummadi, Steven D. Gribble, "A Measurement Study of Peer-to-Peer File Sharing Systems" In Proceedings of Multimedia Computing and Networking 2002
[4] Stephanos Androutsellis-Theotokis and Diomidis Spinellis. A survey of peer-to-peer content distribution technologies. ACM Computing Surveys, 36(4):335–371, December 2004
[5] Bram Cohen, "Incentives Build Robustness in Bittorrent", May 22, 2003. www.bittorent.com
[6] J.A. Pouwelse, P. Garbacki, D.H.J. Epema, H.J. Sips,"The Bittorrent P2P file-sharing system: measurements and analysis". In Proceedings of the 4th International Workshop on Peer-To-Peer, 2005
[7] Ian Clarke, Oskar Sandberg, Brandon Wiley, Theodore W. Hong, "Freenet: A Distributed Anonymous Information Storage and Retrieval System". In Proc. ICSI Workshop on Design Issues in Anonymity and Unobservability, 2000
[8] Freenet 1.4 Protocol, rev 00002. Retrieved 05/04/06 from http://cvs.sourceforge.net/viewcvs.py/freenet/docs/incoming/r4proto.txt?rev=1.3
[9] Rachna Dhamija, "A security Analysis of Freenet". Retrieved 17/04/2006 from http://www.sims.berkeley.edu/~rachna/courses/cs261/paper.html
Other Interesting Literature
[10] Duncan J. Watts, "The 'New' Science of Networks". Annual Review of Sociology, 2004 30:243-70
[11] Mihajlo A. Jovanovic, Fred S. Annexstein, Kenneth A. Berman, “Scalability Issues in Large Peer-to-Peer Networks – A case study of Gnutella”.
[12] Wikipedia.org, “Peer-to-Peer”, http://en.wikipedia.org/wiki/P2P
[13] David Ferguson, “Trends and Statistics in Peer-to-Peer”. Retrieved 19/04/2006 from http://creativecommons.nl/nieuws/wp-content/uploads/2006/04/CacheLogic_AmsterdamWorkshop_Presentation_v1.0.ppt
[14] The Gnutella Protocol Specification v0.4 http://www9.limewire.com/developer/gnutella_protocol_0.4.pdf
[15] Wikipedia.org, “Freenet”, http://en.wikipedia.org/wiki/Freenet
[16] Stephanos Androutsellis-Theotokis, Diomidis Spinellis, “A survey of Peer-To-Peer content distribution technologies”. ACM Computing Surveys (CSUR), 2004
[17] Understanding Peer-to-Peer, www.cachelogic.com/p2p/p2punderstanding.php
4.2 Research Groups/Companies
![]() Parallel and Distributed Systems Group
at the Delft University of Technology, Netherlands
Parallel and Distributed Systems Group
at the Delft University of Technology, Netherlands
![]() Peer-to-Peer Systems Research Group
at Bilkent University: investigate research issues in peer-to-peer systems
and come up with solutions to the problems identified. The focus is on
databases, networking, and security aspects of peer-to-peer computing.
Peer-to-Peer Systems Research Group
at Bilkent University: investigate research issues in peer-to-peer systems
and come up with solutions to the problems identified. The focus is on
databases, networking, and security aspects of peer-to-peer computing.
![]() Gnutella: protocol development
website
Gnutella: protocol development
website
![]() Internet Systems Group at the University of Toronto:
Internet Systems Group at the University of Toronto:
5. SCOPE OF THIS SURVEY
This paper is divided into sections. In the first section of the survey, we examine the concept of P2P computing and its emergence as a popular means of computing especially as a way of sharing content in today’s internet. Next we take an in-depth look at the protocols of 3 thriving P2P network today, Gnutella, Bittorrent and Freenet and how sharing of content is realized in their networks.
The reference material for this survey was obtained from searches for publications found in the ACM digital library, Google scholars and the Wikipedia online encyclopedia. Search result were filtered to obtain only recent publications (at least <= 3years) since world of P2P computing is quickly evolving, and also choice of paper was based on their relevance to the P2P protocols that this survey deals with.